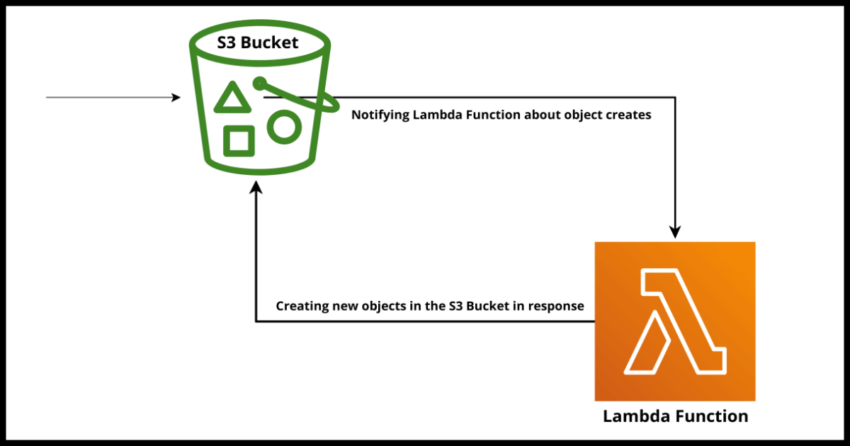
So you are working with the Amazon Cloud Platform – building serverless infrastructure – making use of a Lambda to process objects in real time as they get written to an S3 bucket – maybe you were creating thumbnails out of raw images or doing some other kind of post processing – and you saved the processed or modified object back to the same S3 Bucket – and now the realization sinks in – this Lambda is now in an infinite death spiral loop – reprocessing it’s own processed objects ad infinitum. Not only that – depending on how long this has been going on – you are rightly concerned about yet another out of control spiral – your AWS Bill for that Lambda and the S3 storage space.
How could you let this happen? Well…join the club…happened to so many of us and will continue to happen after this – this is a well worn road. But first let’s fix it! Hit that throttle button on your Lambda.
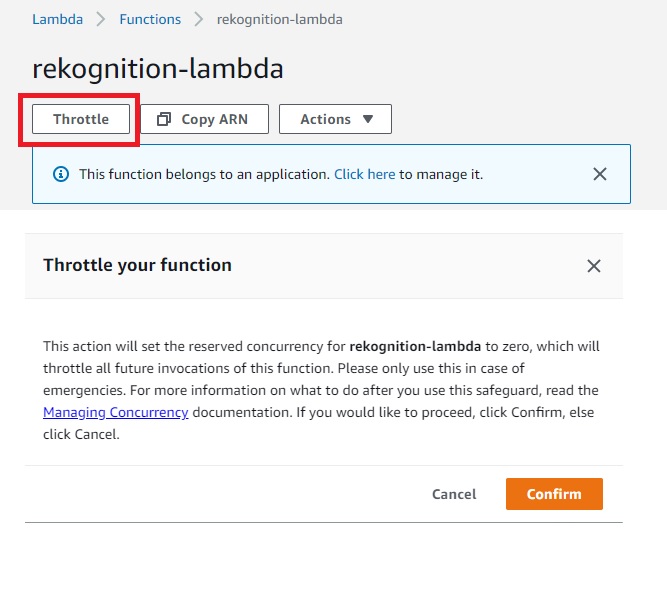
This will first give you the warning that it will set the reserved concurrency of the Lambda to zero which will prevent all future invocations of the Lambda and that it needs to be only done in an emergency. Well – an infinite loop between an S3 Bucket and a Lambda is an emergency so go right ahead.
This is probably the quickest way , but if you have details like the Lambda name and tooling, you can also use the API to effect the same thing:
aws lambda put-function-concurrency --function-name rekognition-lambda --reserved-concurrent-executions 0 You should now be able to validate from your CloudWatch Logs that the Lambda will eventually die down to nothing – phew.
How to avoid this infinite Loop condition
OK now, that we have gained valuable cloud life experience and put out the immediate infinite loop fire – we need to resolve the actual problem before we can update our Lambda by removing its reserved concurrency setting.
There are a few ways – but the most recommended best practice – use two S3 buckets – never have a Lambda write back to an S3 Bucket it received a notification event from – in fact use IAM to ensure the Lambda doesn’t have write access to that bucket. Put your processed objects in a second bucket with no feedback loop to the Lambda function.
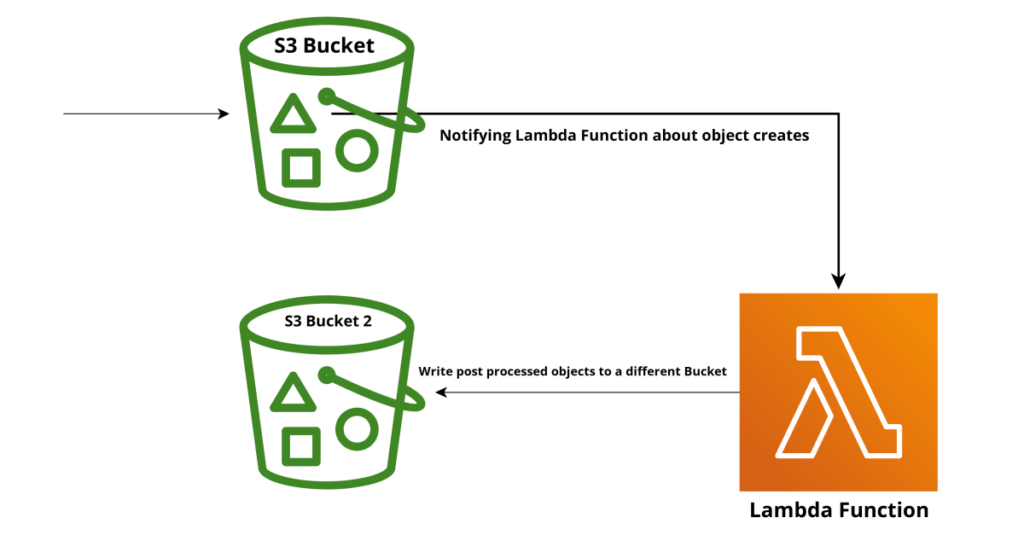
If you cannot use Two Buckets…
There are plenty of valid reasons to not being able to do this – especially if it is a Production Application and switching services feeding front end UIs to a different bucket may be more involved – or there could be multiple consumers of the bucket which again makes switching complicated.
In that case, you need to handle this in code within the Lambda function.
If possible prefix the processed file with some indication – like thumbnail or post-process etc – you probably are renaming the objects anyway when you upload them back to S3 so this shouldn’t be a huge change – and if renaming is not possible – add some metadata or work with metadata to indicate it was a processed image – and add guard code in your function to ignore such objects
if "thumbnail-" in s3_key:
returnAfter this you should be good to remove the 0 reserved concurrency from your Lambda via the settings or by redeploying your Lambda to override the throttle.