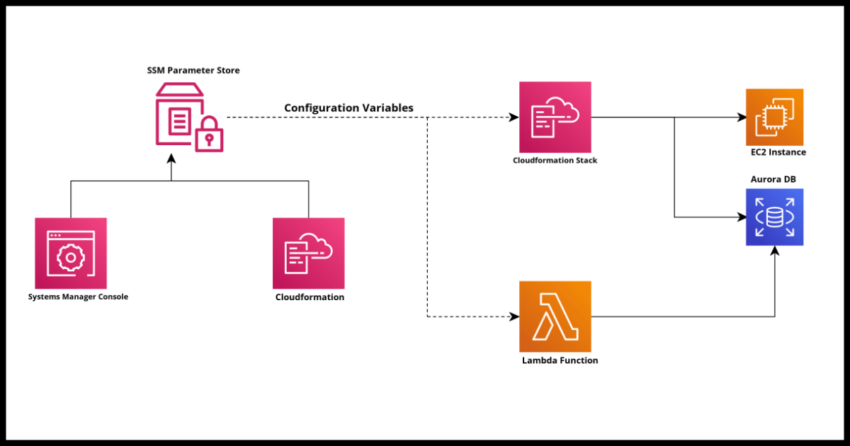
Any moderately complex application will typically have the need to make use of what most of us working with code term as “environment variables”. These are perhaps API or database endpoints that have different values in a production region as opposed to a lower development region along with everything else that may go along with it from access tokens to usernames and password configuration information -all the information that have historically been saved in a environment specific configuration file from which applications are instantiated with in different environments.
The Parameter Store feature under Amazon Web Services’ Systems Manager offering is not going to replace the need for you to manage your own configuration parameter variables – it is however an enhanced way to make managing and using all those parameters a lot easier.
Benefits of the AWS SSM Parameter Store
Reiterating again, this service is not solving or offering a radical replacement for configuration management. End of the day, the process you need to go through to create, use, save and secure your configuration parameters are still your decisions to make. However, there are some clear benefits to using the parameter store if your stack runs on the Amazon cloud platform.
For one, it is a centralized repository. If you make use of the parameter store consistently as a single place, it will save you from the pain of having to hunt down and update values across all your individual application config settings. This is often an extraordinarily tedious job many of us have probably had the misfortune of undertaking when there are major infrastructure changes to a stack like a database migration exercise.
Second, the Parameter store supports a hierarchical key definition for parameters. This is a completely optional but extremely useful feature I strongly encourage you to consider making use of. Now consider moderate to much larger applications or organizations you may have worked with. In my personal experience the number of parameters can significantly increase very quickly and this makes discovering them hard this in turn leads to duplication of the variables pointing to the same resources because someone may not realize there is already a parameter variable for it.
With the Parameter Store’s hierarchical support – variable keys are named like they are part of a directory structure – for example
/databases/mysql/server/url
/databases/mysql/server/port
This hierarchy in the naming structure can make discovery and management of the parameters much more manageable even in a larger organization. Provided of course teams are disciplined about making use of the store in a way that minimizes redundancy.
Next benefit, and a critical one especially for serverless designs and architectures which tend to have multiple loosely coupled microservices and stacks, it is very easy to reference the values either directly in Cloudformation stacks or in code using the AWS SDK for the language of your choice. We will cover this in more detail in the coming sections. If it helps, you could also version your parameters and access specific versions. But me personally I try to avoid this situation in favor of simplicity.
And lastly – from a compliance and security perspective – the AWS Systems Manager Parameter Store has several features ranging from integration with Key Management Service to encrypt extremely sensitive values to audit capabilities where you can use CloudTrail to track access to your parameters to ensure no unexpected or disallowed usage of the parameters occur. In addition, you can wire it up to get parameter access and change notifications. This we will perhaps cover in a separate post, but for now lets dive into how to practically work with the Parameter Store with our applications in its most basic form – creating and referencing parameter values.
Types of supported Parameters
Just a quick note on the types of parameters that can be created.
The most obvious and easily the most commonly used type of parameter is your everyday run of the mill String or Text parameter. This is pretty self explanatory and really wouldn’t make sense to have a centralized environmental variable repository without this. However there are a couple of validation related enhancements that are supported. Firstly, you can specify a type for EC2s – “aws:ec2:image” as the “data type” so that a validation is done to ensure the parameter is a valid EC2 AMI name. Additionally when using Cloudformation, you can specify an allowed pattern using a regular expression.
The other types supported are StringLists – comma, separated values which definitely have their application in a variety of scenarios and SecureStrings – KMS encrypted secure parameters which we will cover in a separate article. However do be aware that you cannot create Secure encrypted parameters with Cloudformation as of now and you will need to use the console or the SDK.
Creating a Parameter in the SSM Console
The process is quite straightforward for a basic parameter.
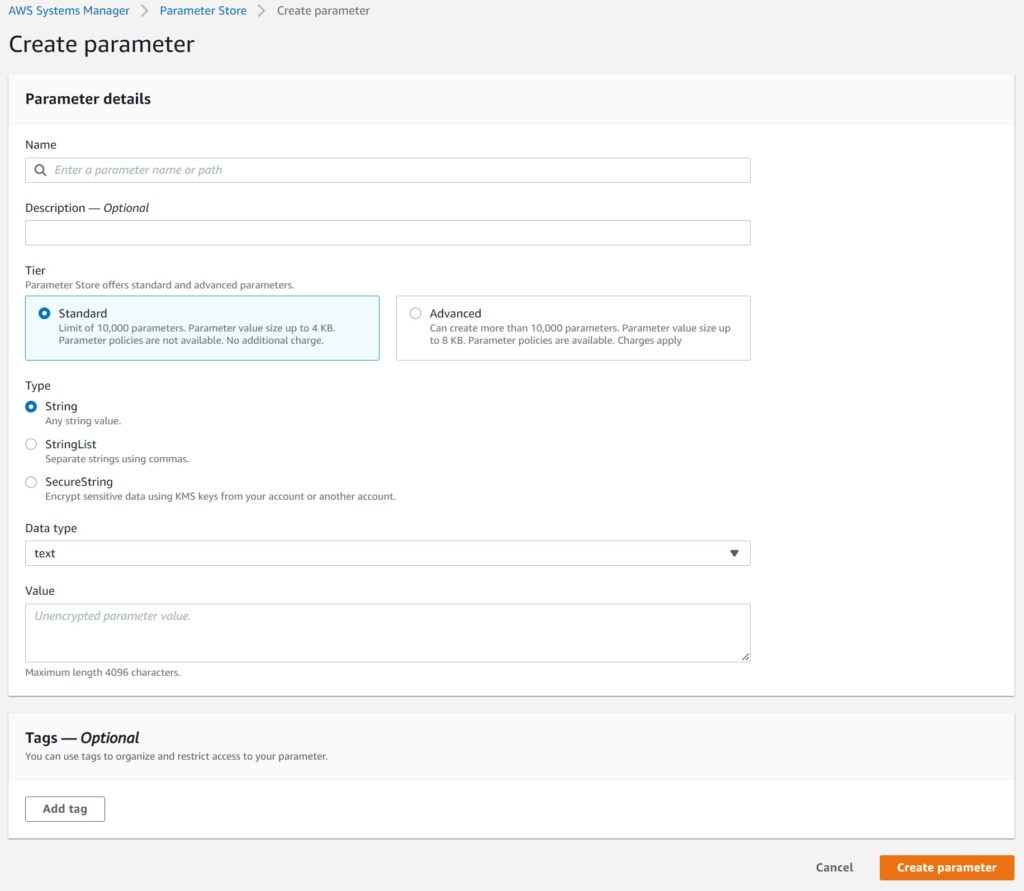
For the name, as I recommended earlier, it is best to make use of the hierarchical structure to organize your parameters.
Regarding the Tiers – if you ever need to make use of more than 10,000 parameters per account, something that is really really dependent on the size of your organization and the usage of your single AWS account within that organization, you can pick the advanced tier – which incurs a charge as opposed to simply using the store at no charge. There is the little extra perk of using IAM policies for your parameters in the advanced tier – something I haven’t personally used but will perhaps investigate and write about if I see a benefit to that practically.
Creating a Parameter via the AWS CLI
The AWS CLI can be used in the following format, going with the example I mentioned above for a hypothetically organized database parameter value.
aws ssm put-parameter \
--name "/databases/mysql/server/url" \
--value "auroradb-example.instanceid.awsregion.rds.amazonaws.com" \
--type String \
Creating a Parameter as a Cloudformation Resource
It is generally considered a best practice to maintain your shared infrastructure cloudformation stacks as separate entities from your regular application stacks that may utilize them. Even in the case of things like API endpoints that may be part of another application stack, it is a good practice to maintain the endpoints perhaps within a separate “Parameter” of “Config” cloudformation stack. I did mention that managing the values of your configuration is still something you have to live with and is not a problem solved by the Parameter Store – just an aid to the process.
MySQLServerURL:
Type: AWS::SSM::Parameter
Properties:
Name: /databases/mysql/server/url
Description: Aurora MySQL RDS Server Url
Type: String
Value: auroradb-example.instanceid.awsregion.rds.amazonaws.comThere are other options that can be configured for more complex scenarios such as the validation property and so on but for a basic string parameter, the above is all there is to creating one.
If you would like to see more details on working with Cloudformation Templates, please see my article on this subject here.
Referencing a Parameter Store value in a Cloudformation Stack
There can be two ways you reference something from the store. In many cases, you may want to use this just within the context of your cloudformation template to configure something without actually using this in code.
The classic example is perhaps to assign permissions to a resource to some other resource that is not part of the application stack but is defined perhaps elsewhere and can be referenced via the parameter store. Like say granting a Lambda permission to an S3 Bucket.
LambdaFunctionResource:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.9
CodeUri: ./bucket-reader/
Handler: bucket-reader.lambda_event_handler
FunctionName: bucket-reader
Policies:
- Version: 2012-10-17
Statement:
- Effect: Allow
Action: s3:GetObject*
Resource: !Sub
- "arn:aws:s3:::${bucketparam}*"
- bucketparam: "{{resolve:ssm:/s3/buckets/bucket_name:1}}"The magic is all in the resolve:ssm: placeholder which cloudformation will then use to retrieve the desired parameter from the store and initialize your application stack with.
Referencing a Parameter Store value in Lambda Code
Now there are two ways to make use of the parameters with the code of a Lambda.
One is to use the resolve:ssm: placeholder to simply pass the value in as an environmental variable to the Lambda directly like so.
LambdaFunctionResource:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.9
CodeUri: ./parameter-user/
Handler: parameter_user.parameter_handler
FunctionName: parameter-user
Environment:
Variables:
MYSQL_SERVER: "{{resolve:ssm:/databases/mysql/server/url:1}}"
Which can then be simply accessed in the Lambda code like this Python example
import os
mysql_server = os.environ["MYSQL_SERVER"]
def parameter_handler(event, context):
print(f"{mysql_server}")
...
...
...However sometimes for any reason you may want to retrieve those values at runtime. This would certainly be necessary for encrypted parameters. In such a case, we can seamlessly do this with the AWS SSM SDK – which I demonstrate below using the Python Boto3 SDK.
import boto3
ssm = boto3.client('ssm')
def parameter_handler(event, context):
...
...
mysql_server_param_details = ssm.get_parameter(Name='/databases/mysql/server/url')
mysql_server = mysql_server_param_details["Parameter"]["Value"]
...
...It returns the entire parameter object with other metadata related to it, but more importantly the value we need from the store which we can now utilize in code.
And that wraps things up for this article on the basics of using the Parameter Store for config information.