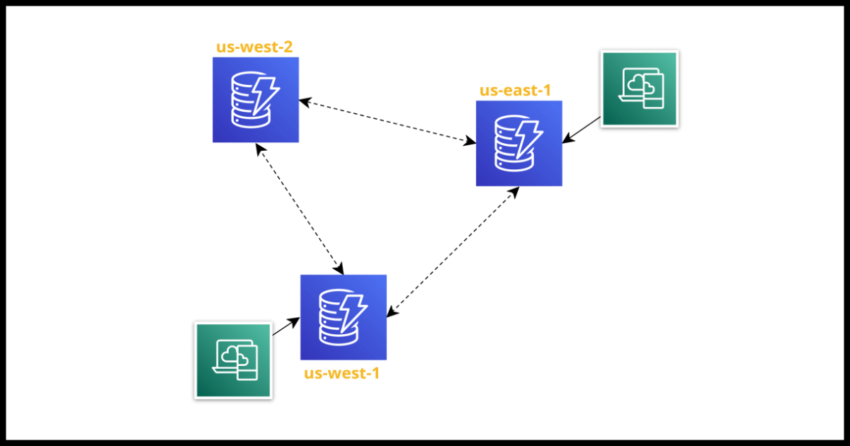
If there is even a slight possibility that you might want to replicate your dynamodb data for any reason – disaster recovery (DR) needs – scaling your application to get closer to your customer bases – to work with some other application in another region – don’t start out with the AWS::DynamoDB::Table cloudformation resource and go directly with Global Tables: AWS::DynamoDB::GlobalTable.
With Global Tables you have scalability and recovery baked in for the future, even if you don’t need it immediately! It just makes the switch to replicating your existing data seamless and managed for you when you decide to go for it. Otherwise your options are as tedious as any data migration exercise even with Dynamodb
This post will cover two things:
- First, demonstrate how to create a Dynamodb Global Table using cloudformation – nice and easy!
- And then show why you should definitely, and I mean most definitely keep your Global Tables in a separate cloudformation stack from the rest of your application – because it would defeat the whole purpose by preventing you from being able to replicate the rest of the stack!
Creating a DynamoDB Global Table with Cloudformation.
In a nutshell –
- Design it as you would any regular good old dynamodb table thinking of your access patterns and using single table design.
- Set the type to AWS::DynamoDB::GlobalTable
- Set the Stream Specification – because there is no special sause AWS uses for replicating your data in global tables and it needs dynamodb streams.
- And most importantly provide the Replicas property which is a list of regions to replicate to.
- To start with lets just set this to a single region.
This is how a simple table would look like.
GlobalTable:
Type: AWS::DynamoDB::GlobalTable
Properties:
TableName: my-replicating-table
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES
Replicas:
- Region: us-east-1
AttributeDefinitions:
- AttributeName: primary_key
AttributeType: S
KeySchema:
- AttributeName: primary_key
KeyType: HASHThat is really all there is to it.
And now when you need replication in the future, simply extend the replica list.
Replicas:
- Region: us-east-1
- Region: us-east-2
- Region: us-west-1And why you should keep this separate from other resources in the stack
Nothing like demonstrating the problem. Lets say we include a Lambda to reference the table in the same stack…
GlobalTable:
Type: AWS::DynamoDB::GlobalTable
Properties:
TableName: my-replicating-table
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES
Replicas:
- Region: us-east-1
- Region: us-east-2
AttributeDefinitions:
- AttributeName: primary_key
AttributeType: S
KeySchema:
- AttributeName: primary_key
KeyType: HASH
Lambda:
Type: AWS::Serverless::Function
Properties:
Policies:
- DynamoDBReadPolicy:
TableName: !Ref GlobalTableThis will work when you create the stack in the first region, say us-east-1. And will create the replica dynamodb in use-east-2. But if you next try to deploy your Lambda to the second region – it will not allow you because the table already exists.
Perhaps AWS will handle this scenario in the future – but for the moment, you really need to keep your dynamodbs in a separate stack. And in fact, there are benefits to keeping critical infrastructure like databases separate in any case as it would minimize the risk of accidentally deleting the stack if someone forgot to set:
DeletionPolicy: Retain
UpdateReplacePolicy: RetainIn either case, the solution I like to use is to simply reference the global table names in other stacks as parameters, like so.
Parameters:
GlobalTable:
Type: String
Default: my-replicating-table
Lambda:
Type: AWS::Serverless::Function
Properties:
Policies:
- DynamoDBReadPolicy:
TableName:
Ref: GlobalTableAnd that I find to be a nice consistent pattern to managing stacks.